
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
My URL: http://welcome.to/lokeang
![]()
Architecture Definition of the Intel MMX (TM) Technology
Carole Dulong
Intel Santa Clara Processor Division
Abstract
Intel’s MMXTM technology [1] is an extension to the Intel Architecture (IA) designed to improve performance of multimedia and communications algorithms. The technology includes new instructions and data types that can be used by applications to achieve a new level of performance on the host CPU [2]. MMX technology exploits the parallelism inherent in many of these algorithms using SIMD (Single Instruction Multiple Data) technique while maintaining full compatibility with all existing IA microprocessors, operating systems, and applications.
1. Motivation
Motivation for MMX technology is exploiting the data parallelism present in multimedia and communication applications. Most of these applications, like MPEG video, music synthesis, speech compression, image processing, games, speech recognition or video conferencing use algorithms which execute the same operations on multiple data. This type of parallelism is commonly referred to as SIMD for Single Instruction Multiple Data. For example in image processing, applying a filter to an image means executing the same sequence of operations on all the pixels of the image. Even in a small image of 640x480 pixels, there are more than 300,000 pixels. Obviously the same set of operations is executed a large number of times, and executing these operations in parallel on multiple pixels at once does speed up the algorithm execution time.
In the case of imaging, data operated on are 8-bit wide, and the same is true in video processing. For audio algorithms most data are 16-bit audio samples. Executing 8-bit or 16-bit operations in 32-bit wide or 64-bit wide functional units of today’s microprocessor is not efficient.
In summary, a very significant fraction of the time spent in processing multimedia or communication applications is spent in routines which have the following characteristics:
Small native data types (for example: 8-bit pixels, 16 bit audio samples)
Regular memory access patterns: most often data which could be operated on in parallel are at consecutive addresses in memory
Compute-intensive: many of the target applications are compute bound, and not memory bound.
These characteristics make these applications ideal candidates for SIMD type acceleration. MMX technology provides this acceleration by processing independent small elements in parallel, and by enabling full utilization of the wide processing units of the CPU.
2. Goals
The MMX technology definition team had very crisp goals. These goals are:
End User Visible Benefits
Most target applications have real time requirements. It is essential that performance benefits of any extensions be visible for the user. They could be a noticeable higher frame rate, a better image quality, or new capabilities enabled in an application.
General Purpose
The MMX instructions are meant to be part of all Intel future CPUs. Applications and algorithms will evolve with time. It is important to define instructions which are general enough to be usable for several generations of multimedia technology.
Small silicon cost
OS transparent
One very important requirement for the extension was backwards compatibility with existing IA processors. It was imperative that MMX technology add a substantial new robust capability to the IA while maintaining 100% backward compatibility. All existing software written for Intel Architecture processors would have to continue to run (without modification) on an Intel processor that also supports the extension and in the presence of applications that use MMX technology. This compatibility guideline also meant that MMX technology be fully compatible with all existing operating systems; that is, MMX applications should be able to run in all existing Software environments.
3.0 Home for Multimedia Data
The simplest way for a general purpose microprocessor to exploit data parallelism on 8 bit or 16 bit data is to pack independent data elements in registers, and operate on these elements in parallel. The wider the register, the more parallelism can be exploited. The goal of OS transparency means that no new architectural state could be added. New registers would not have been known of existing Operating Systems, and would not have been saved on context switches. Integer registers are only 32 bit wide and would have limited the amount of parallelism and potential speed up, so floating point registers were chosen for multimedia data. However floating point registers in the Intel Architecture are organized in a stack which makes programming difficult, so multimedia registers are mapped onto the floating point registers, but are organized as 8 independent registers. This organization achieves its full compatibility with existing operating systems and applications. No new registers, condition codes or events are added to support MMX technology. MMX registers use to the low order 64 bits (the mantissa) of the 80-bit floating point registers.
The dual usage of the floating point registers does not preclude applications from using both MMX and floating point code. Applications though, should not attempt to use the registers for FP and MMX data at the same time. As the values in FP registers are interpreted differently when accessed by FP instructions or MMX instructions, the user should not rely on register content across transitions between MMX and FP code. Partitioning the floating point code and MMX code into execution phases makes transition events infrequent and simple to deal with.
Floating-point instructions that save/restore the floating-point state also handle the MMX state (for example, during context switching). For all practical purposes an existing operating system views MMX technology as if it was a new use of the floating point registers.
Floating point registers in the Intel Architecture have tag bits indicating their content and validitity, which are used to trigger stack underflows and overflows. All multimedia instructions set the tag bits of all MMX registers to their busy state. A new instruction called EMMS (Empty MMX State) has been added. It should be issued at the end of all routines using MMX instructions, for the usage of MMX registers not to interfere with floating point routines which may be called after multimedia routines. EMMS resets all tag bits to the empty state.
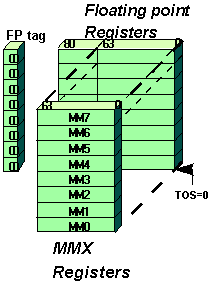
Figure 1. Mapping of MMX™ Registers to the Floating Point Registers
In summary: MMX instructions use eight new 64-bit general purpose registers which are mapped on the floating point registers. Each can be directly addressed within the assembly by designating the register names MM0 - MM7 in MMX instructions. (Figure 1)
4. MMX Technology Features
This section describes the following features of MMX technology:
The new data types of small data elements packed together into one register
The enhanced instruction set that operates on all data elements of a register in parallel in a SIMD fashion.
4. 1. New Data Types
MMX technology defines 4 new packed data types (see figure 2): packed bytes, packed words, packed double words, and Quadwords. Packed bytes are most useful for graphics and video applications manipulating pixels. Packed words are most useful for audio and communication applications manipulating 16 bit audio samples for example. Packed double words are of general use, and are specially useful to hold intermediary results in algorithms which need to keep 32 bit of precision for running accumulators. Packed Quadwords are used for bitwise operations, and for alignment operations.
Each element within a packed data is a fixed point integer. The programmer controls the place of the fixed point within each element and is responsible for its placement throughout the calculation. While this adds programming burden, this gives a large amount of flexibility to vary fixed point formats during application executions in order to adapt to dynamic range requirements.
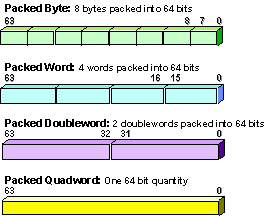
Figure 2. MMX™ Technology Packed Data Types
4. 2. Enhanced Instruction Set
MMX technology defines a rich set of instructions that perform parallel operations on multiple data elements packed into 64 bits (8x8-bit, 4x16-bit, or 2x32-bit fixed-point data elements). Overall, 57 new MMX instructions are added to the Intel Architecture.
MMX instructions operate on different data types, and support operations on both signed and unsigned operands. MMX arithmetic instructions come in two different flavors: wrap around arithmetic and saturating arithmetic. In wrap around arithmetic, when an operation overflows or underflows, the most significant bits are lost. For example, addition of two unsigned 16-bit numbers residing each in a 16-bit register may result in an unsigned 17-bit result, a number too large to be represented in a 16-bit register. The low-order 16 bits of the result appear in the result register, but the 17th bit is truncated. With saturating arithmetic, the result is clamped to the largest possible unsigned number representable in a 16-bit register: FFFFh, if the result cannot be represented in 16 bits (Figure 3) .Saturating arithmetic avoids the need to check for overflow.
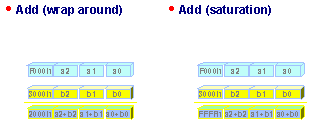 Figure 3. Wrap Around versus Saturating
Arithmetic
Figure 3. Wrap Around versus Saturating
Arithmetic
Saturating arithmetic is supported for 8-bit and 16-bit data, and for signed and unsigned data. For bytes, unsigned saturation is expected to be most useful for pixel operations. Wrap around arithmetic would cause pixels to become brighter and brighter, and suddenly jump to black when the wrap around happens. Clamping pixel values to the brightest color (FFh) is the most natural way to handle these cases. Similarly signed saturation is expected to be useful for operations on audio samples (typically signed 16-bit elements) where saturating at highest and lowest possible values is built in many algorithms.
MMX technology supports a packed compare instruction. Given the constraint of not adding any new architecture visible state, this instruction could not return any new flags. The result of PCMP is a mask containing all 0’s if the tested condition is false, and all 1’s if the tested condition is true. (Figure 4)

Figure 4. Packed Compare Instruction
This resulting mask can be used in a variety of ways. One possibility is to perform a conditional move operation (Figure 5). By performing a logical AND with the mask, elements of vector Y are moved in where the condition is true. By performing a logical AND COMPLEMENT, elements of vector X are moved in where the condition is false. A logical OR between these two intermediary results gives a result where Y has been selected where the condition is true, and where X has been selected where the condition is false. This conditional move is executed without the need for any branch instruction, which makes it very efficient. Branch instructions are to be avoided when exploiting data parallelism since they can be seen are serializers.
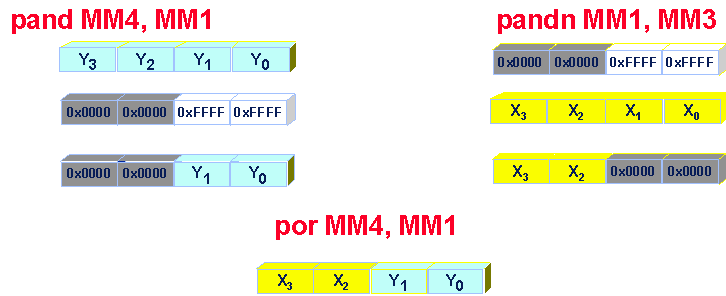
Figure 5. Conditional Move Operation
The following table summarizes the instructions defined by MMX technology:
Opcode |
Description |
| Padd[b/w/d] Psub[b/w/d] |
add & subtract with optional saturation |
| Pcmpeq[b/w/d] Pcmpgt[b/w/d] |
compare equal or greater than |
| Pmullw Pmulhw |
16-bit multiply Result low or high-order bits |
| Pmaddwd | 16-bit multiply-add. 32-bit results |
| Psra[w/d] Psll[w/d/q] Psrl[w/d/q] |
shift count in register or immediate |
| Punpckl[bw/wd/dq] Punpckh[bw/wd/dq] |
Interleave merge |
| Packss[wb/dw] | pack with saturation |
| Plogicals | and, or, xor, and-not |
| Mov[d/q] | move 32/64-bit |
| EMMS | empty MMX state |
Table 1. MMX™ Instruction Set Summary. Data type support, byte (b), word (w), doubleword (d), or quadword (q) listed in brackets.
5. Examples of MMX™ Instruction Usage
The PMADDWD instruction computes four 16-bit x 16-bit multiplies generating four 32-bit products, and then adds the first pair and the second pair of these products together. Figure 6 shows how the PMADDWD instruction operating in parallel on four elements of a vector can be used for a vector dot product computation. The result of the PMADDWD are added to the running accumulator of the inner loop by a PADDD instruction. The two elements of the accumulator need be added together outside of the inner loop to get the final result of the dot product
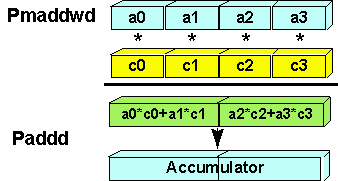
Figure 6. Flow Diagram of a Vector Dot Product
A lot of consideration was given to data manipulation instructions when defining MMX instructions. MMX technology speeds up computations when data elements are adjacent in memory or in registers. It is important to have fast mechanisms to place elements in adjacent locations when this format is not their natural one. Executing operations in parallel on multiple data is efficient if the overhead of exploiting the parallelism is small.
The Unpack instruction interleaves either the low or the high elements of both operands as shown in the following figure. If the "b elements" are zero in this example, the Unpack operations effectively performs a conversion of the "a elements" from unsigned words into double words.
![]() Figure 7. Unpack Low Words into Double Words
Figure 7. Unpack Low Words into Double Words
Another frequent use of the Unpack instruction is the transposition of an array. When data are organized in memory in rows (a0, a1, a2, a3) for vector A, and similarly for vectors B, C, D, but the data parallelism is on the columns i.e. (a0, b0, c0, c0), a transposition is necessary to use the MMX instructions. Vectors A and B are interleaved as shown in the previous figure, similary Vectors C and D are interleaved.
![]()
A final Unpack instruction on the two intermediary results gives the first set of results (Figure 8). Note that it is unpacking double words into quadwords. An unpack high of these same two intermediary results gives the second set of results. A similar sequence of Unpack operations is necessary to get the last two results.
![]() Figure 8. Transposing an Array with Unpack
Figure 8. Transposing an Array with Unpack
The pack instruction is very useful at the end of routines which carry computations in 16-bit for example to keep enough precision during execution, but need 8 bit results (Figure 9). The pack instruction supports signed and unsigned saturation when packing 16-bit elements into 8-bit elements. This means that the packed element is either the largest or the smallest possible value in 8 bits if it cannot be represented with 8 bits.
![]() Figure 9. Pack Words into Bytes
Figure 9. Pack Words into Bytes
6. Summary
The following chart (Figure 10) shows the application level performance benefits of MMX instructions. The different applications are represented along the x axis, the y axis represents the speed up of the application using MMX technology over the same application not using MMX technology in the same micro-architecture (PentiumTM Processor with MMX Technology). Speed up factors depends on two key elements:
how much time is spent in routines which can benefit from MMX instructions. For example applications which spend only 50% of their time in routines which exhibit data parallelism can at most be sped up by a 2x factor if the time spent in the parallel routine is reduced to zero. This explains the speed up measured for the MPEG1 video decoder. It is modest but user visible, and is limited by the time spent in parallel routines.
data types used in the application. Routines using 32 bit elements can at most be sped up by 2x, but routines using 8 bit elements can be sped up by up to about 8x. For applications using saturating arithmetic, the speed up can actually be higher than 8x: saturating arithmetic reduces to one instruction, a long sequence of instructions which test for overflow and clamp the result. The Image Filter application exhibits a very high speed up. It spends over 80% of its time in parallel routines, it works on pixels (byte wide), and it makes use of saturating arithmetic. All three factors contribute to this very high speed up.
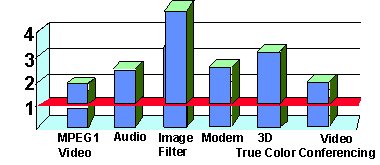
Figure 10. Application Speedups using MMX Technology
IA MMX technology has been implemented first on a Pentium processor proliferation (Pentium Processor with MMX Technology), and on the Pentium II processor. It will now be part of all future Intel Architecture processors. MMX technology has become a base capability of all Intel CPUs enabling new performance levels and new applications on the PC. MMX technology introduces general purpose data types and instructions which are expected to benefit current and future applications exhibiting data parallelism.
Acknowledgments
MMXTM technology is the results of the work of a large team of Intel architects and software developers. The list of names is too long to fit here, but many thanks to all of them.
References
[1] Alex Peleg, Uri Weiser, "MMX Technology Extension to the Intel Architecture", IEEE Micro, Vol. 16, No. 4, August 1996, p42-50.
[2] Mike O’Conner, "Extending Instructions for Multimedia", Electronic Engineering Times, No. 874, November 1995, p82.
[3] Intel Corporate Literature, "i860TM Microprocessor Family Programmers Reference Manual," Intel Corporate Literature Sales, 1991.
[4] Keith Deifendorff, Michael Allen, "Organization of the Motorola 88110 Superscalar RISC Microprocessor", IEEE Micro, April 1992, p40-63.
[5] Ruby B. Lee, "Subword Parallelism with MAX-2," IEEE Micro, Vol. 16, No. 4, August 1996, p51-59.
[6] M. Tremblay, et al. "The Visual Instruction Set (VIS) in UltraSPARC," Compcon Spring 95, March 5-9 1995.